Luthfi Raditya

Resume | LinkedIn | GitHub | Medium
I am an aspiring Data Scientist with a passion for using business, data, and technology to create something that positively impacts society. I have a deep specialization in constructing machine learning models, which makes me a T-shaped individual.
I blog about AI/ML/Data Science and my personal experience. Outside of work, I enjoy sports, reading non-fiction, and binge-watching!
Portofolio
Data Science
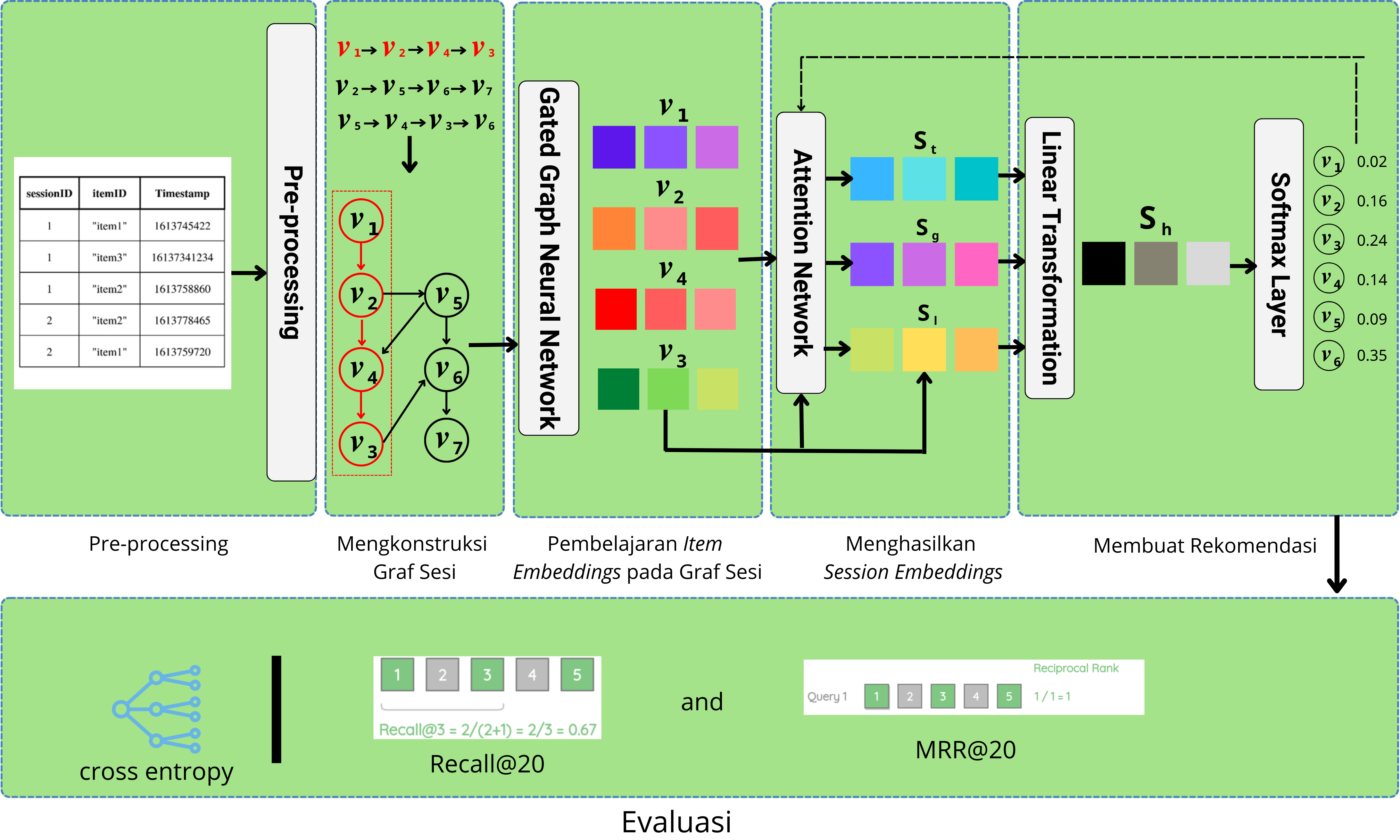
Thesis : Session-based Recommendation System using Gated Graph Neural Network and Attention Mechanism on E-commerce Dataset
The primary objective of this research is to develop a session-based recommendation system that leverages a Gated Graph Neural Network (GGNN) to amalgamate global preferences, current interests, and user-specific preferences.
The research encompasses several stages, including data pre-processing, session graph construction, item embedding, session embedding, recommendation generation, and model evaluation.The research findings demonstrate that the proposed model exhibits superior performance compared to other models on both datasets. In the Yoochoose dataset, the Recall@20 achieved an impressive 70.81%, with MRR@20 reaching 31.05%. Meanwhile, the Diginetica dataset yielded a Recall@20 of 50.08% and an MRR@20 of 17.80%. These results signify the model's effectiveness in providing top-tier recommendations.
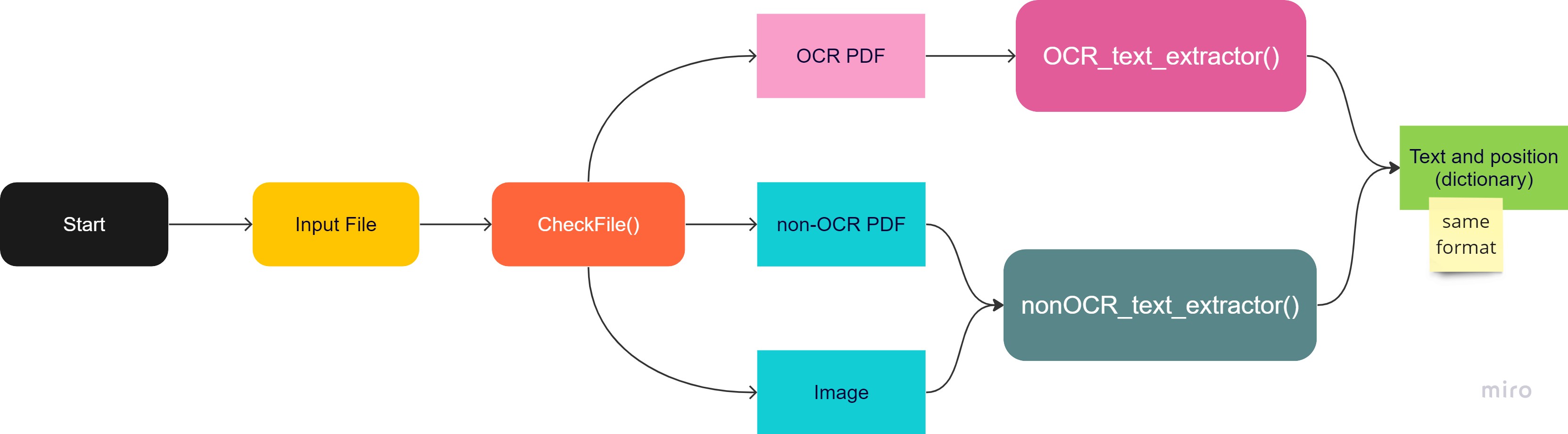
Named Entity Recognition (NER) using LayoutLM
Working on a project that involves utilizing LayoutLM, a multimodal Transformer model designed for document image understanding and information extraction. This technology has promising applications in text comprehension and receipt understanding. Named Entity Recognition, a critical task, involves the identification and categorization of entities like individual names, organizations, locations, dates, and more within a given text. The innovative aspect of LayoutLM lies in its extension of this task to encompass the visual layout of text. This includes factors such as the positioning of text, font styles, and formatting details. Through my project, I am creating a system that can automatically extract and categorize named entities present in various documents. By combining the capabilities of language comprehension with visual layout analysis, I aim to achieve a more accurate identification of entities. This approach becomes particularly valuable in cases where conventional NER methods face challenges due to the diverse formats and structures of documents.
Original LayoutLM paper: https://arxiv.org/abs/1912.13318
LayoutLM docs in the Transformers library: https://huggingface.co/transformers/model_doc/layoutlm.html
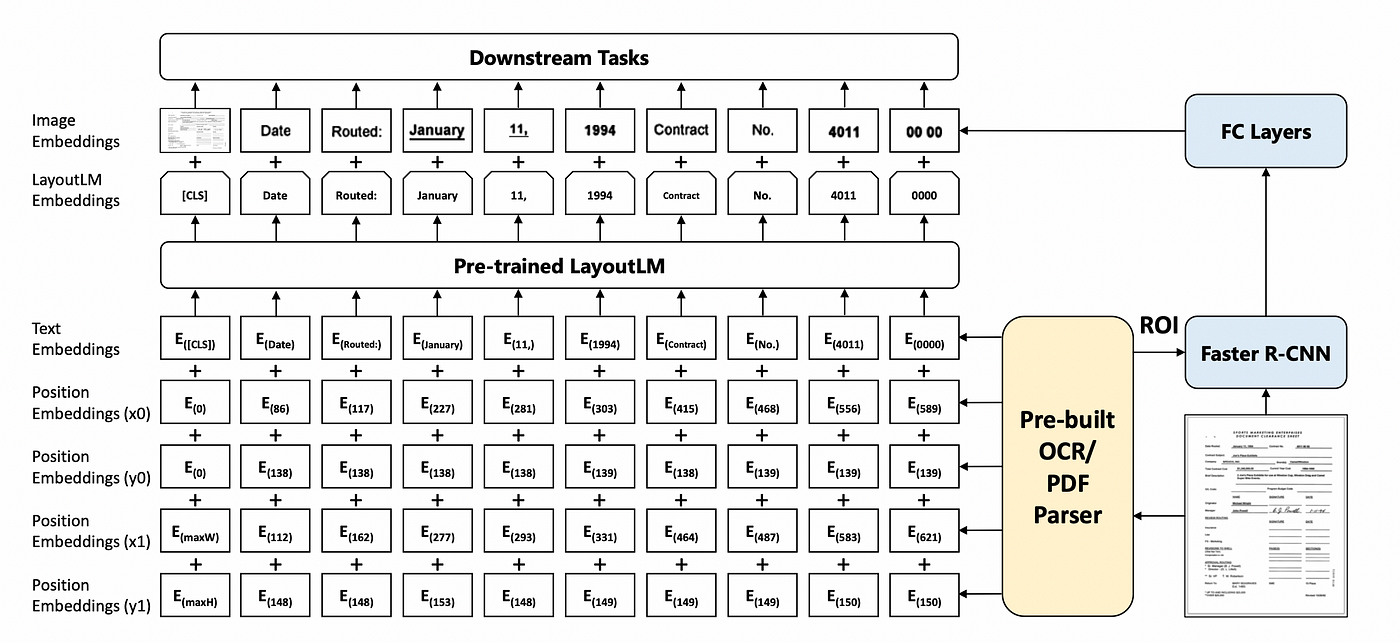
Document Classification using LayoutLM
In this project, I am exploring document classification using LayoutLM, a pre-trained model for document image understanding. The goal of this project is to provide an overview of how to use LayoutLM for document classification, including how to prepare the data, fine-tune LayoutLMForSequenceClassification the pre-trained model, and evaluate its performance on RVL-CDIP dataset. By the end of this project, we should have a good understanding of how to use LayoutLM for document classification and be able to apply these techniques to document classification tasks.
Original LayoutLM paper: https://arxiv.org/abs/1912.13318
LayoutLM docs in the Transformers library: https://huggingface.co/transformers/model_doc/layoutlm.html
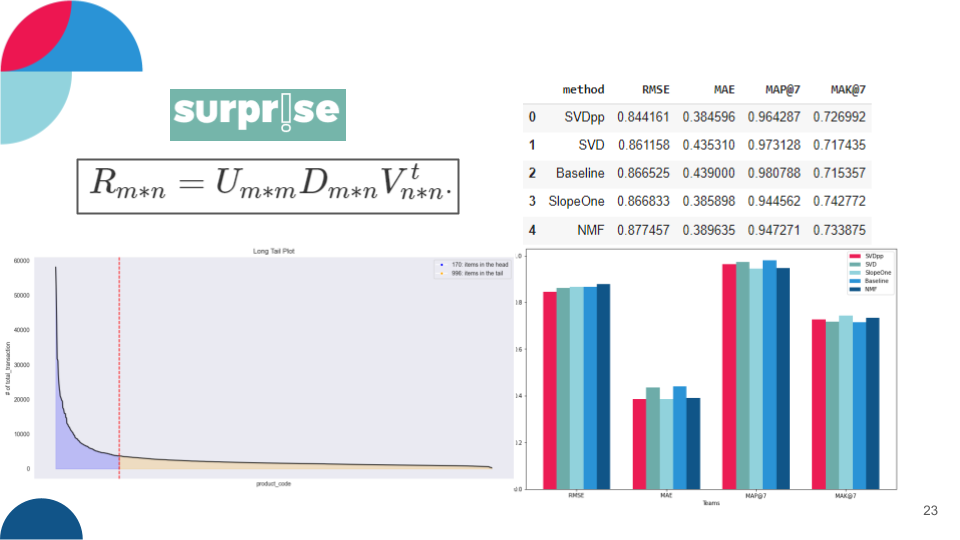
Recommender Systems on E-commerce
This project is a pilot project during internship. I built recommender systems for recommending products to user using Model-based recommendation system. The goal of this project is to make a recommendation system model that is more accurate than the previous model. The model achieve the best performance with SVD++ where this model gets an RMSE score of 0.844 and MAE 0.384. I also use the mlflow tool to do experiment tracking.
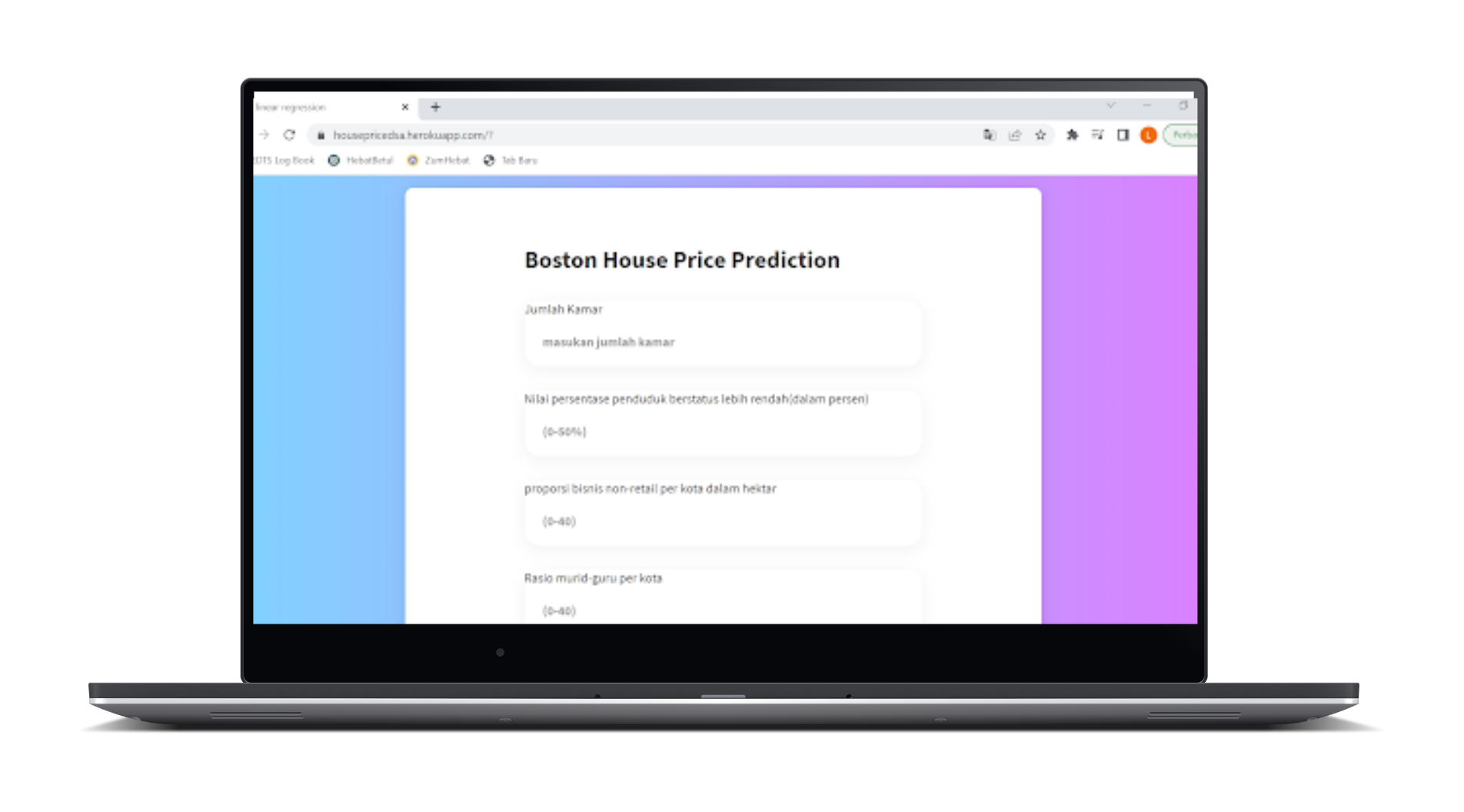
Boston Housing Prediction with deployment
This project was started as a motivation for learning Machine Learning Algorithms and to learn the different data preprocessing techniques and implement the concept of Homodescascity, Multicollinearity & Error terms distribution during data exploration. I also deploy this project in heroku. This model get R2 score of 73% and RMSE of 5.09.
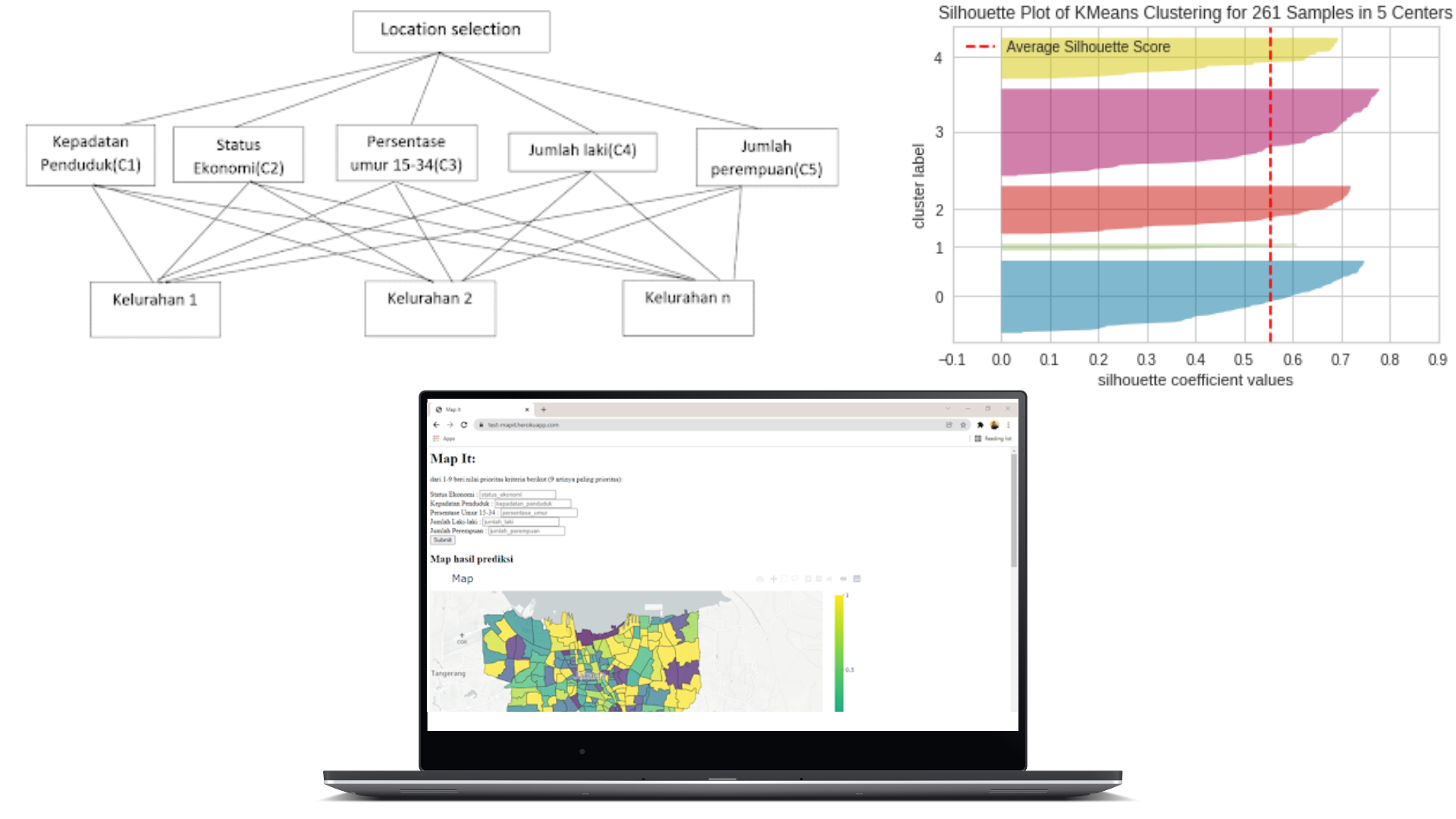
Location Recommendation for Retail
The purpose of this project is to provide location recommendations for retailers who want to open offline stores. This project used to build the startup for the final project called Map.it and succeeded in becoming the five best final projects during MBKM event.
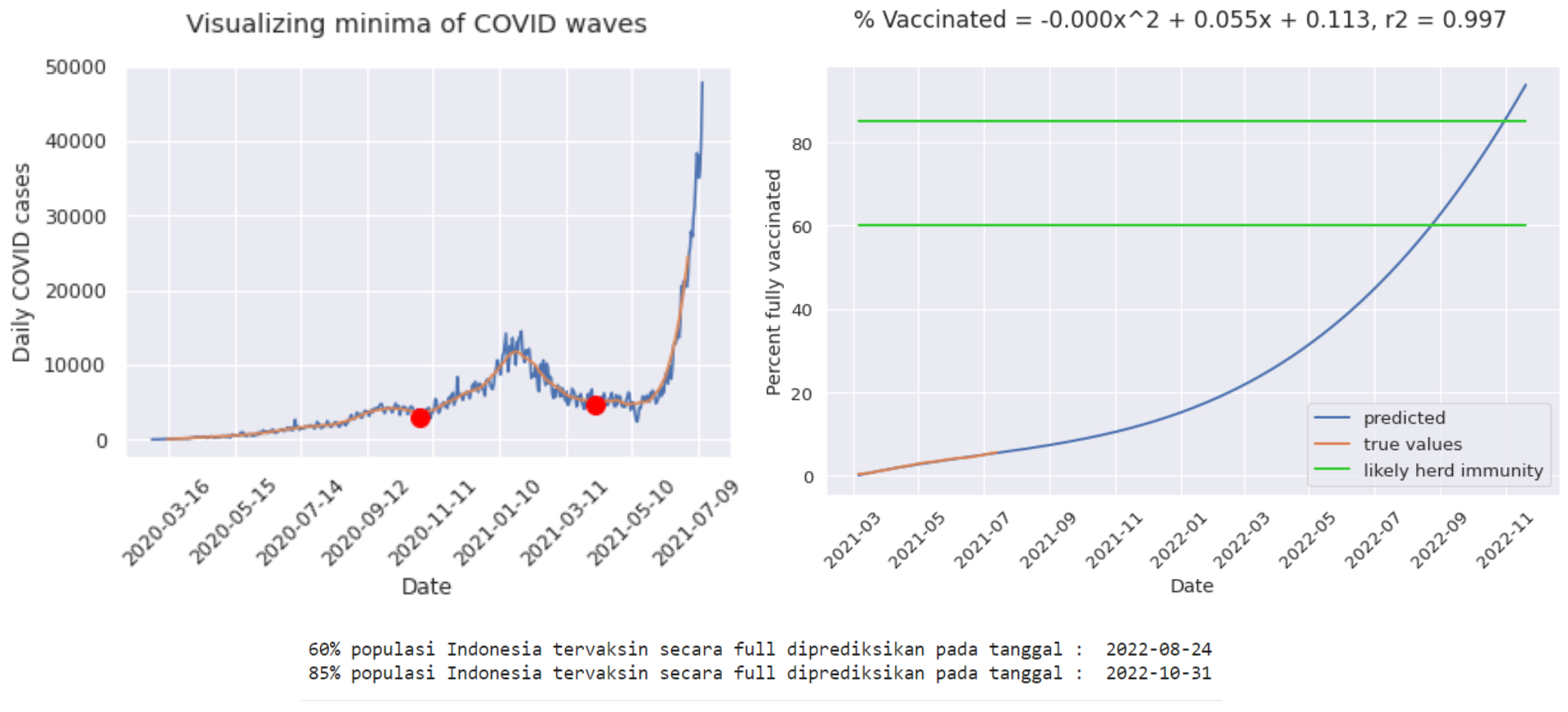
Herd Immunity Prediction
This project aims to predict when Indonesia will reach 60-85% herd immunity with COVID-19 vaccinations. Performing time series analysis and modeling with polynomial models. Using degree=3 as the best degree that gets a score of r2=0.963.
Market Basket Analysis
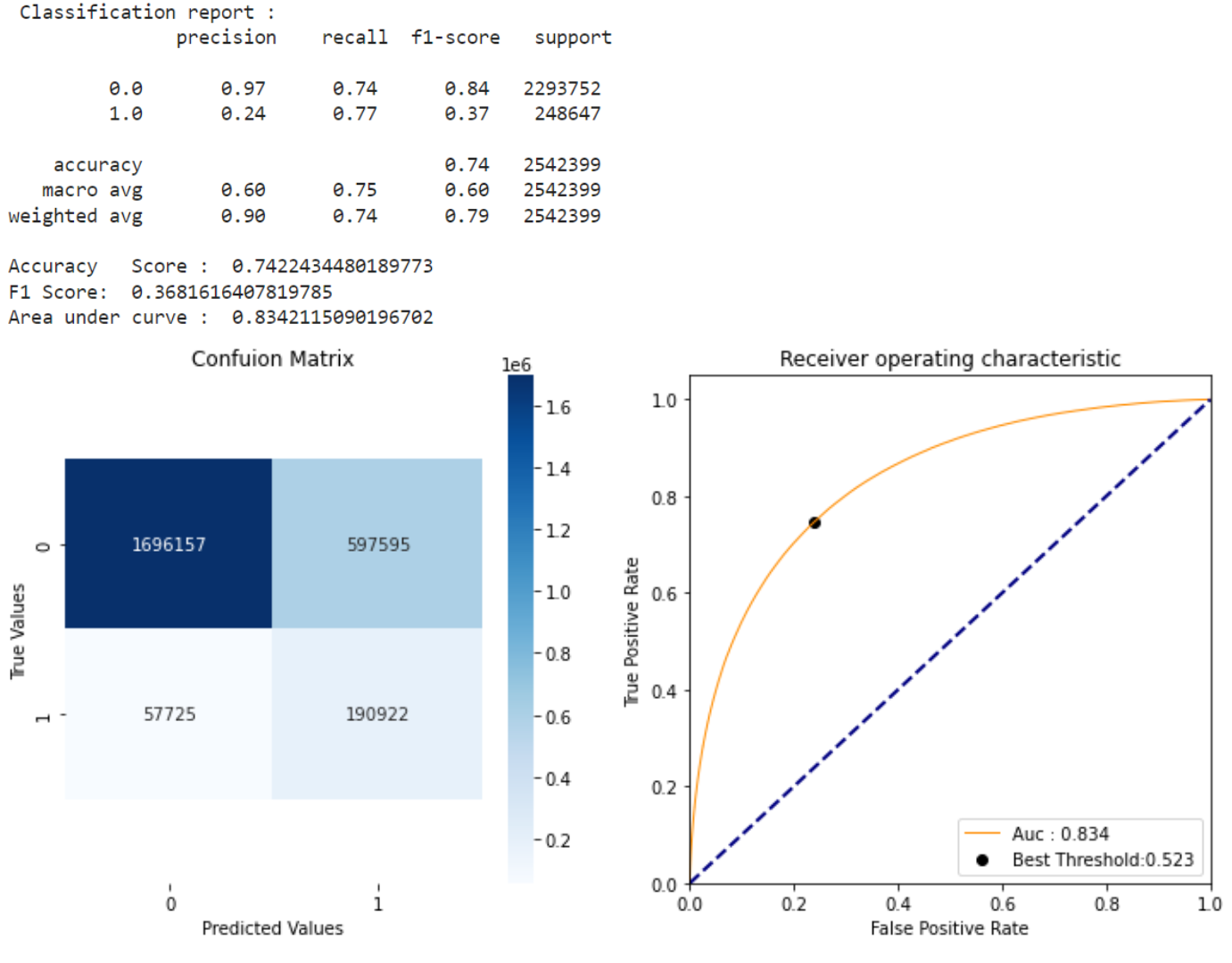
The objective of this project is to analyze the 3 million grocery orders from more than 200,000 Instacart users and predict which previously purchased item will be in user's next order. Customer segmentation and affinity analysis are done to study customer purchase patterns and for better product marketing and cross-selling. Achieved the best performance using the XGBoost model with an AUC score of 0.83, an accuracy of 0.74 and an F1-score of 0.36.
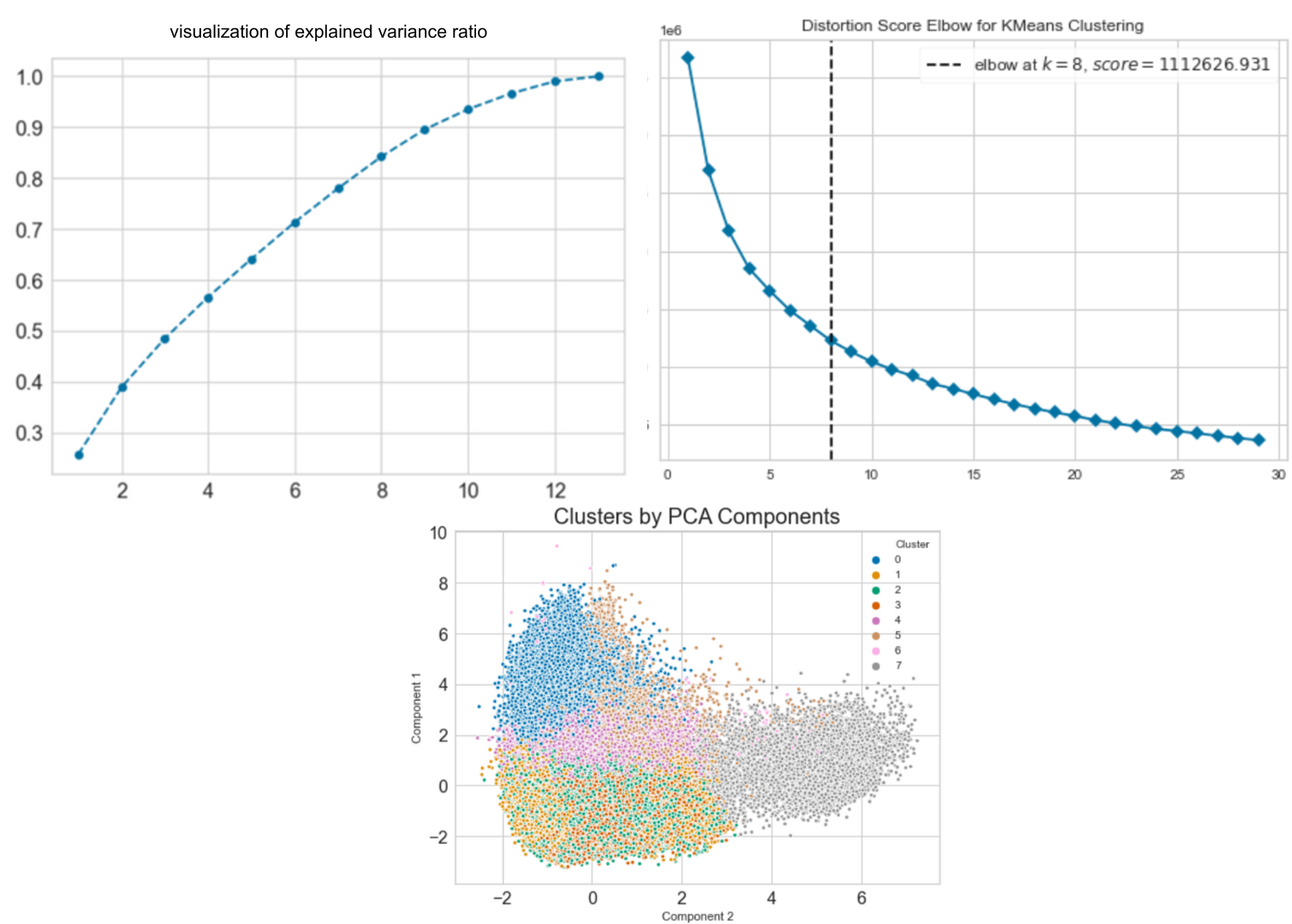
Song Clustering using K-Means
Using song data in the form of components in the song such as acousticness, energy, instrumentalness etc. Reduce data from 13 data variables into 8 components and can be used in K-Means modeling K-Means++. clustering songs into 8 n_clusters.
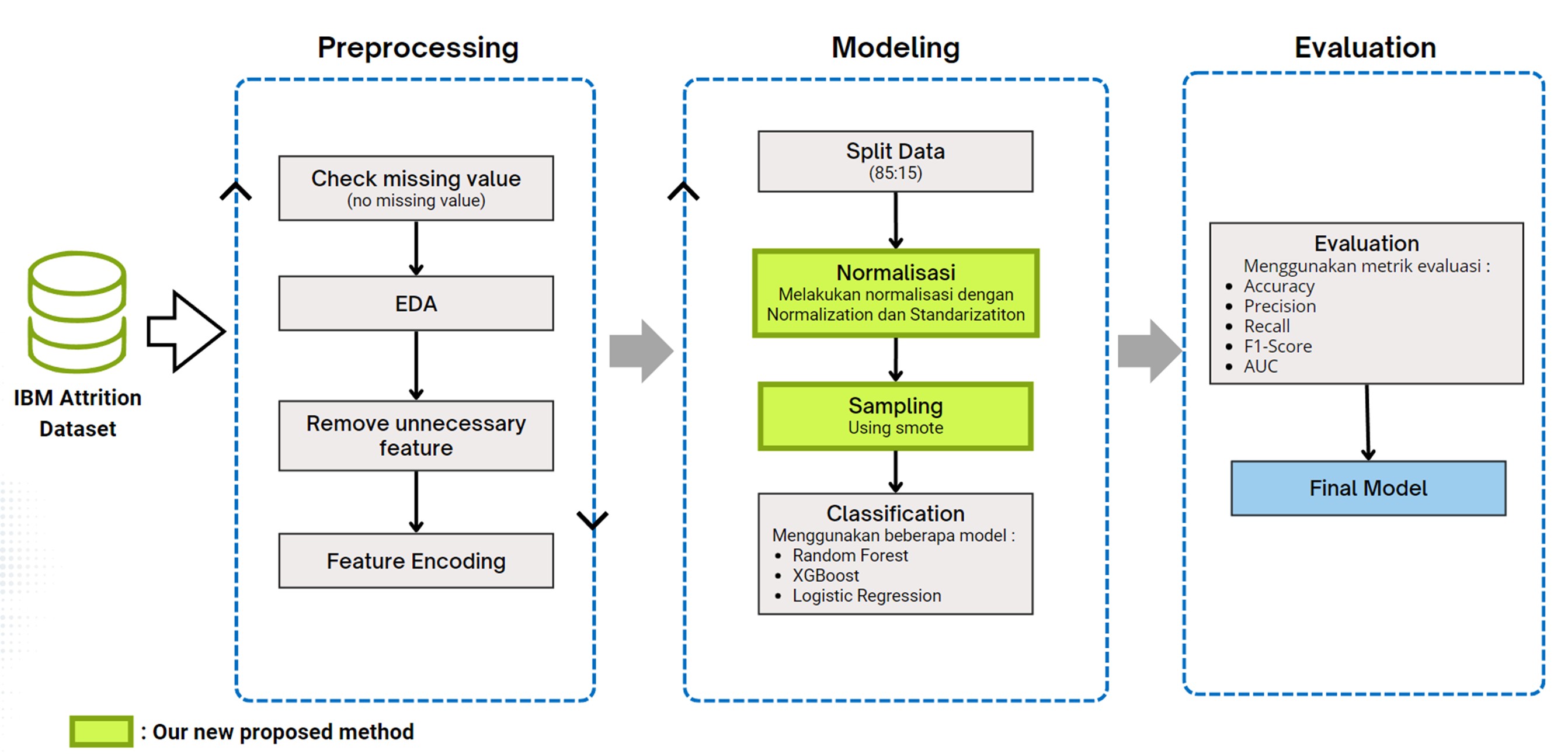
Attrition/Turnover Prediction
In this project I conducted analysis and predictions related to turnover on employee data in a company. Analysis is carried out to look for factors that cause turnover while predictions are used to predict which employees will make turnover. This project also carried out several techniques such as normalization and sampling (due to imbalanced data). After modeling using several classification models, especially the tree algorithm, it was found that LightGBM produced the best performance with F1-score = 91% and ROC-AUC Score = 91%.This project uses kedro as a framework.
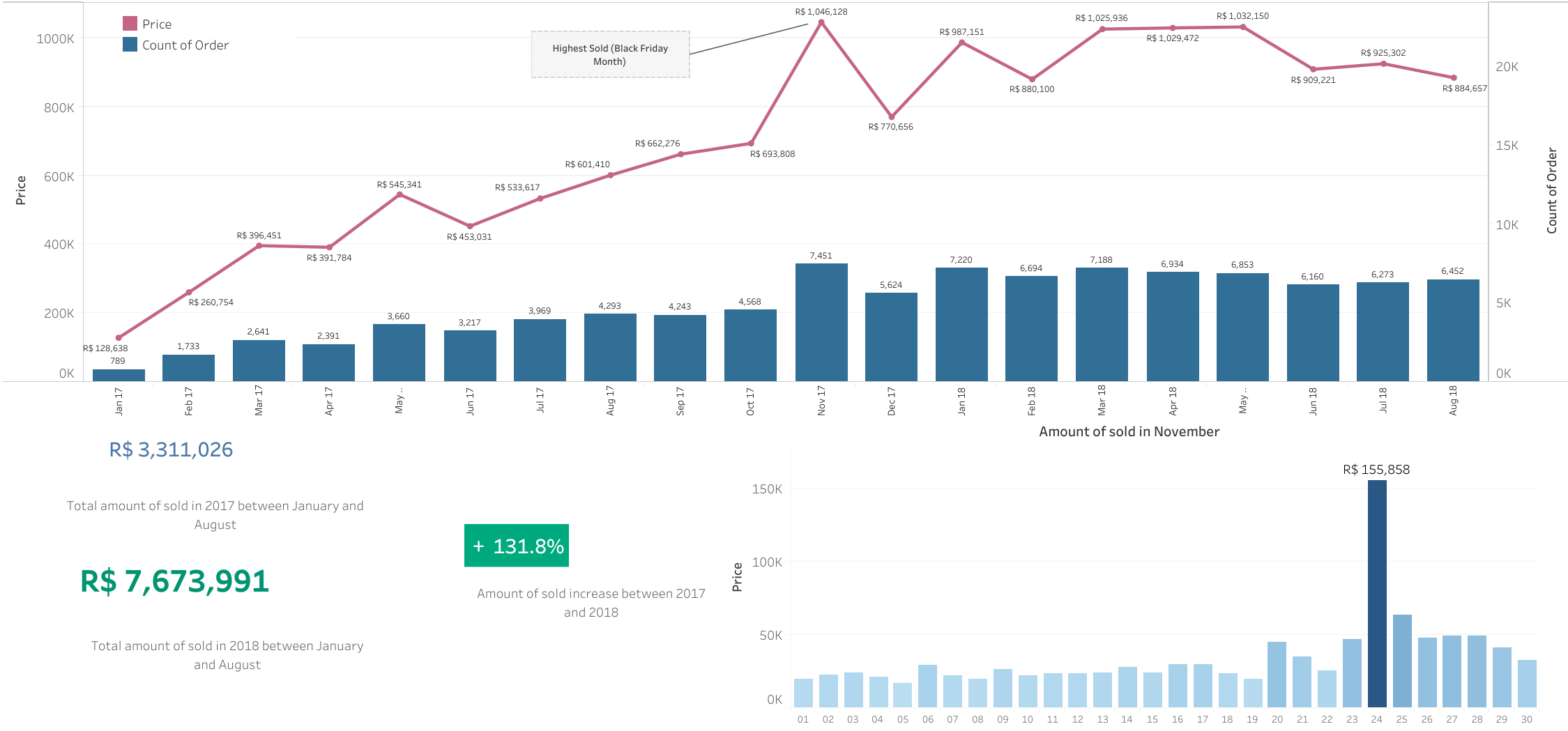
Data Analyst
Olist E-Commerce Business Performance
In this project we have some objective to do about the bussiness performance inside Olist. I do analysis and visualization using tableau. This analysis and visualization focuses on orders and transactions that occurred at olist during 2017 and 2018.
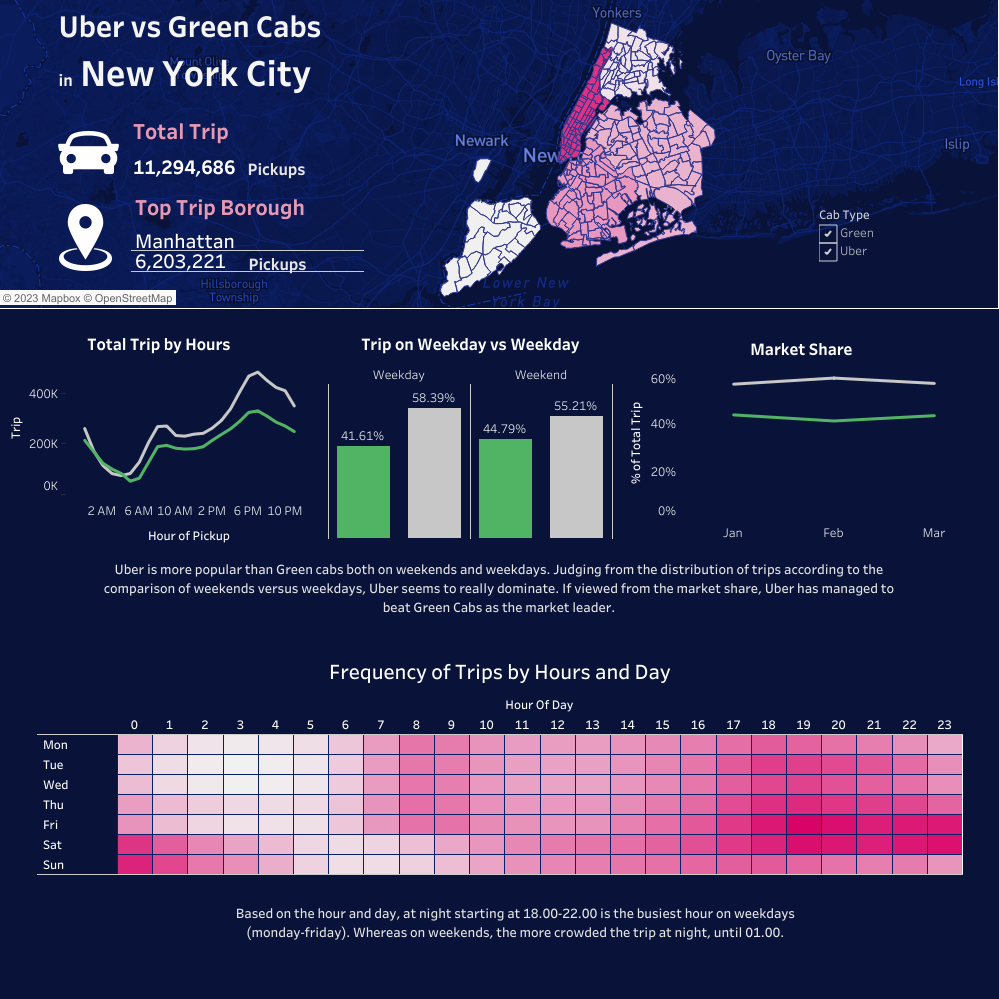
Uber vs Green Cabs Trip in New York City - an Analysis
Analyzing the performance of Green Cabs and Uber Taxi through visual analysis of passenger trips using Green Cabs and Uber Taxi from January to June in 2015 in the New York City area. Broadly speaking, there are two questions related to the research conducted:
How do Green Cabs and Uber rides compare regionally in neighborhoods outside of New York City?
Do customer preferences change according to the time of day (night/day or weekend/weekday)?
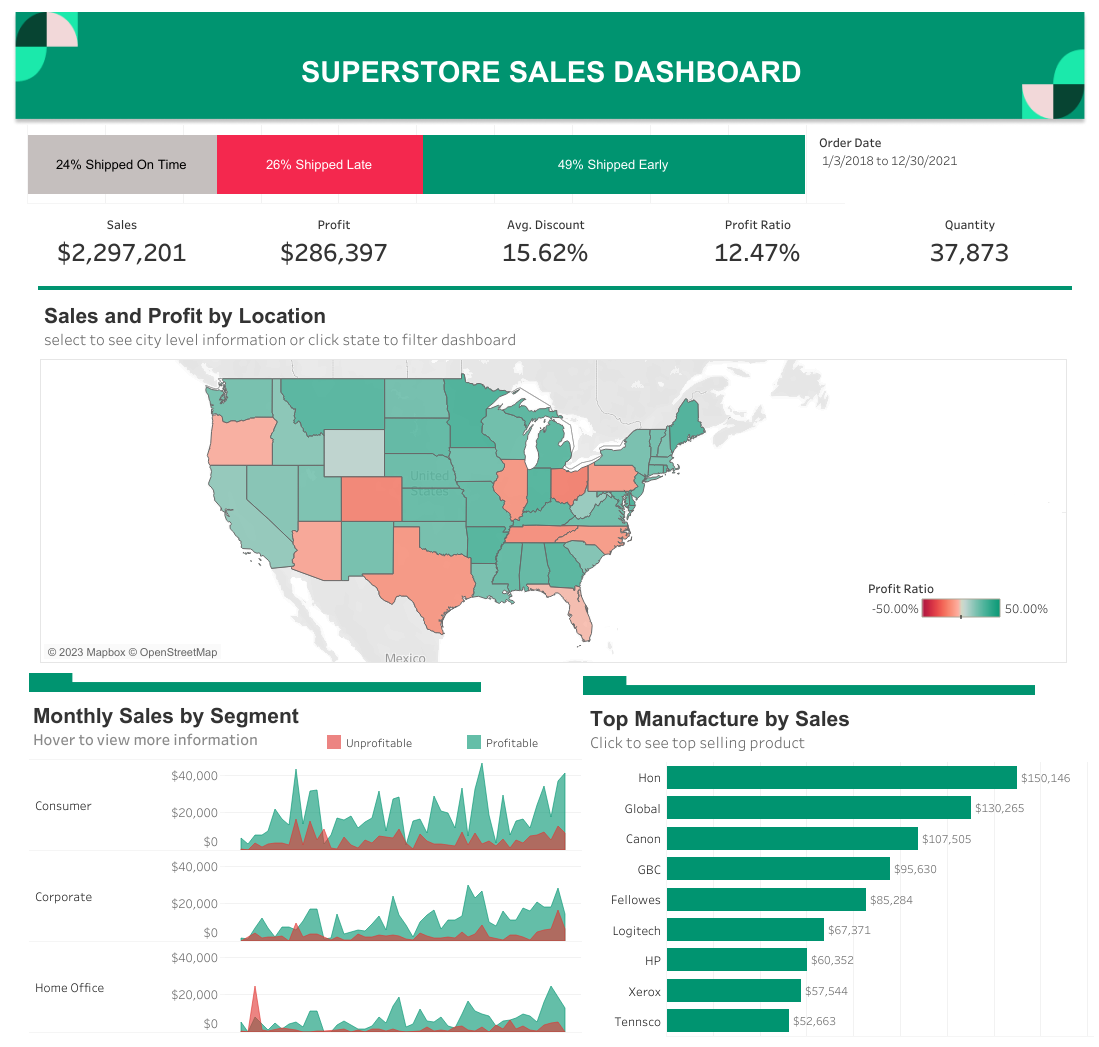
Superstore Sales Dashboard
Created a superstore dashboard showing the sales & profit by location, segment analysis, category analysis, shipping analysis in various years of a superstore. In this project also, I have made a interactive Tableau Sales Dashboard and find some insights from the data.